
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 자료구조
- 자바스터디
- 이펙티브 자바
- 이팩티브 자바
- 스프링부트와AWS로혼자구현하는웹서비스
- DDD
- 인프런김영한
- 네트워크
- jpa
- CleanCode
- 기술면접
- 알고리즘분석
- 혼공SQL
- 자바
- AWS
- aop
- AWS RDS
- 자바예외
- 도메인 주도 개발 시작하기
- MariaDB
- 인덱스
- react
- mysql
- java
- vue.js
- 이펙티브자바
- 클린코드
- 인프런백기선
- SQL쿡북
- 알고리즘
- Today
- Total
기록이 힘이다.
트리 순회 본문
웹 검색 엔진을 소개
검색 엔진의 요소를 설명하고, 위키피디아에서 페이지를 다운로드하고 파싱하는 웹 크롤러라는 첫 번째 응용 프로그램을 소개. 또한, 깊이 우선 탐색의 재귀적 구현과 후입선출 스택 구현을 위해 자바 Deque 인터페이스를 사용하는 반복적 구현을 제공.
Search engine - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Software system that is designed to search for information on the World Wide Web The results of a search for the term "lunar eclipse" in a web-based image search engine A search engine
en.wikipedia.org
구글이나 빙 같은 웹 검색 엔진은 일련의 검색어를 받아 그와 관련된 웹 페이지 목록을 반환합니다.
<<검색 엔진의 필수 요소>>
1. 크롤링 crawling
웹 페이지를 다운로드하고 파싱하고 텍스트와 다른 페이지로의 링크를 추출하는 프로그램
2. 인덱싱 indexing
검색어를 조회하고 해당 검색어를 포함한 페이지를 찾는 데 필요한 자료구조
3. 검색 retrieval
인덱스에서 결과를 수집하고 검색어와 가장 관련된 페이지를 식별하는 방법
크롤러의 목표는 일련의 웹 페이지를 발견하고 다운로드하는 것입니다.
HTML 파싱하기

크롤러가 페이지를 다운로드하면 HTML 페이지를 파싱하여 본문과 링크를 추출해야 합니다. HTML 파싱의 결과는 본문과 태그 같은 문서 요소를 담고 있는 문서 객체 모델(DOM) 트리입니다. 이 트리는 노드로 이루어진 연결 자료구조로, 각 노드는 텍스트와 태그, 다른 문서 요소를 나타냅니다.
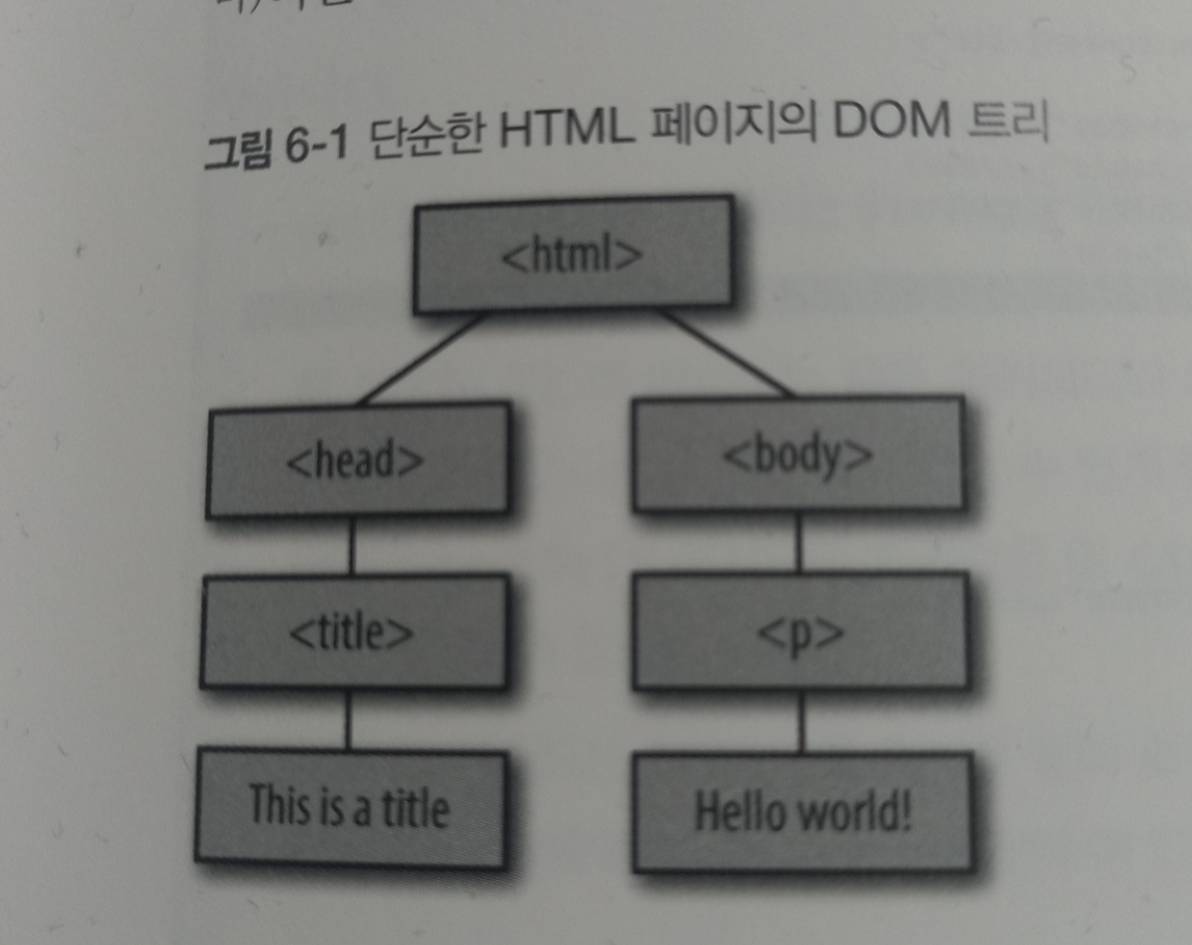
각 노드는 자식 노드에 대한 링크를 포함합니다. 또한, 각 노드는 부모 노드에 대한 링크도 포함하고 있어서 트리를 위아래로 탐색할 수 있습니다. 실제 페이지의 DOM 트리는 보통 이 예제보다 훨씬 복잡합니다.
깊이 우선 탐색
트리를 탐색하는 방법은 응용 방법에 따라 몇 가지가 있습니다. 먼저 깊이 우선 탐색(depth-first search, DFS)는 트리의 루트에서 시작하여 첫 번째 자식 노드를 선택합니다. 자식이 자식을 가지고 있따면 첫 번째 자식을 다시 선택합니다. 자식이 없는 노드에 도착하면 부모 노드로 거슬러 올라가고 부모 노드에 다음 자식이 있다면 그쪽으로 이동합니다. 다음 자식이 없다면 다시 거슬러 올라갑니다. 루트의 마지막 노드까지 탐색하면 종료합니다.
DFS를 구현하는 방법에는 재귀적 방법과 반복적 방법 두 가지가 있습니다. 재귀적 구현은 단순하고 우아합니다.

스택은 리스트와 유사한 자료구조로, 요소의 순서를 유지하는 컬렉션입니다. 스택과 리스트의 주요한 차이점은 스택이 좀 더 적은 메서드를 제공한다는 것입니다. 일반적인 규약에서 다음 메서드를 제공합니다.
push 스택의 최상단에 요소를 추가합니다.
pop 스택의 최상단에 있는 요소를 제거하고 반환합니다.
peek 최상단의 요소를 반환하지만 스택을 수정하지는 않습니다.
isEmpty 스택이 비어 있는지 알려 줍니다.
POP 메서드는 항상 최상단의 요소를 반환하므로 스택은 LIFO (last in, first out)
스택의 대안인 Queue 는 입력한 순서대로 요소를 반환하는 FIFO(first in, first out)
왜 스택과 큐가 유용한지는 명확해 보이지 않습니다. 리스트보다 적은 기능을 제공하는데 왜 모든 경우 리스트를 사용하지 않을까?
1. 메서드의 개수를 작게 유지하면(즉, 작은 api) 코드는 가독성이 높아지고 오류 발생 가능성도 줄어듭니다. 예를 들어, 리스트를 사용하여 스택을 표현하면 우연히 잘못된 순서로 요소를 제거할 수도 있습니다. 스택 API에서는 이러한 실수가 발생할 수 없습니다. 오류를 피하는 가장 좋은 방법은 오류가 발생하지 않게 하는 것입니다.
2. 자료구조에서 작은 API를 제공하면 효율적으로 구현하기가 더 쉽습니다. 예를 들어, 스택을 구현하는 단순한 방법은 단일 연결 리스트를 사용하는 것입니다. 요소를 스택에 push하면 리스트의 시작에 요소를 추가합니다. 요소를 pop하면 시작에서 요소를 제거합니다. 연결 리스트에서 시작에 요소를 추가하고 제거하는 것은 상수 시간 이므로 이 구현은 효율적입니다. 반대로 큰 API는 효율적으로 구현하기 어렵습니다.
반복적 DFS
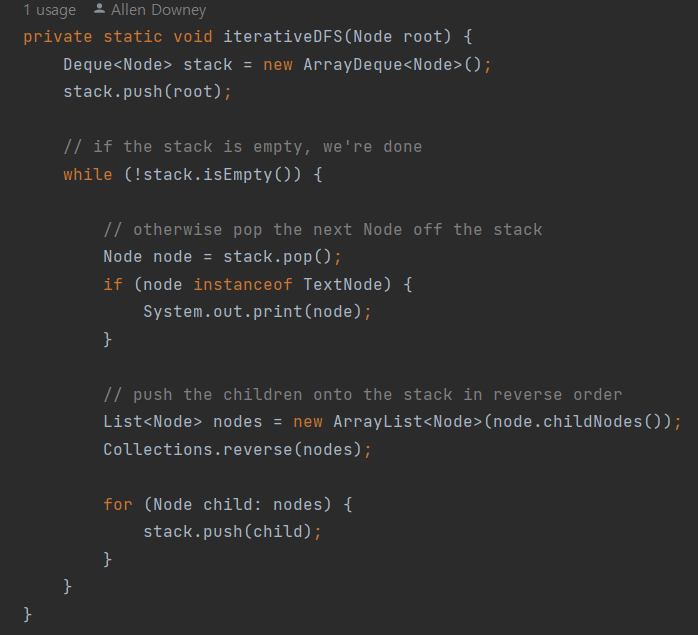
반복적 DFS의 장점은 자바 Interator로 구현하기 쉽다는 것입니다.
ArrayDeque 클래스 말고도 자바는 LinkedList 를 통해 List와 Deque 인터페이스를 둘 다 구현합니다.
'JAVA > 자료구조와 알고리즘' 카테고리의 다른 글
| 인덱서 (0) | 2022.07.02 |
|---|---|
| 철학으로 가는 길 (0) | 2022.06.29 |
| 이중 연결 리스트 (0) | 2022.06.23 |
| LinkedList 클래스 (0) | 2022.06.22 |
| ArrayList 클래스 (0) | 2022.06.20 |

