
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 자바
- 자료구조
- 스프링부트와AWS로혼자구현하는웹서비스
- DDD
- 이팩티브 자바
- 알고리즘분석
- 클린코드
- 기술면접
- 이펙티브 자바
- 알고리즘
- MariaDB
- 인프런백기선
- 자바스터디
- 혼공SQL
- aop
- AWS RDS
- react
- SQL쿡북
- 네트워크
- AWS
- 이펙티브자바
- CleanCode
- 인덱스
- vue.js
- 인프런김영한
- jpa
- java
- 도메인 주도 개발 시작하기
- 자바예외
- mysql
- Today
- Total
기록이 힘이다.
[도메인 주도 개발 시작하기] 4. 리포지터리와 모델 구현 본문
JPA를 이용한 리포지터리 구현
리포지터리 기본 기능 구현
-ID로 애그리거트 조회하기
-애그리거트 저장하기
public interface OrderRepository{
Order findById(OrderNo no);
void save(Order order);
}@Repository
public class JpaOrderRepository implements OrderRepository {
@PersistenceContext
private EntityManager entityManager;
@Override
public Order findById(OrderNo id) {
return entityManager.find(Order.class, id);
}
@Override
public void save(Order order) {
entityManager.persist(order);
}
}구현을 보여주기 위한 것, 평소 스프링 데이터 jpa를 사용함.
스프링 데이터 JPA를 이용한 리포지터리 구현
- 지정한 규칙에 맞게 리포지터리 인터페이스를 정의하면 구현객체를 만들어 스프링 빈으로 등록해줌
- 인터페이스를 직접 구현하지 않아도 되기 때문에 쉽게 정의할 수 있음
public interface OrderRepository extends Repository<Order, OrderNo> {
Optional<Order> findById(OrderNo id);
void save(Order order);
}@Service
public class CancelOrderService{
private OrderRepository orderRepository;
public cancelOrderService(OrderRepository orderRepository, ...) {
this.orderRepository = orderRepository;
..
}
@Transactional
public void cancel(OrderNo orderNo, Canceller canceller) {
Order order = orderRepository.findById(orderNo)
.orElseThrow(() -> new NoOrderException());
if(!cancelPolicy.hasCancellationPermission(order, canceller)) {
throw new NoCancellablePermission();
}
order.cancel();
}
}OrderRepository를 기준으로 엔티티를 저장하는 메서드
Order save(Order entity)
void save(Order entity)
조회할 때
Order findById(OrderNo id)
Optional<Order> findById(OrderNo id)
프로퍼티를 이용해서 엔티티를 조회
List<Order> findByOrderer(Orderer orderer)
중첩 프로퍼티
List<Order> findByOrdererMemberId(MemberId memberId)
엔티티를 삭제하는 메서드
void delete(Order order)
void deleteById(OrderNo id)
매핑 구현
엔티티와 밸류 매핑
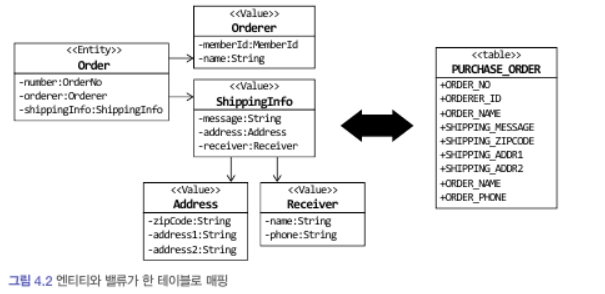
@Entity
@Table(name="purchase_order")
public class Order {
...
}@Embeddable
public class Orderer {
// MemberId에 정의된 컬럼 이름을 변경하기 위해
// @AttributeOverride 애너테이션
@Embedded
@AttributeOverrides(
@AttributeOverride(name = "id", Column = @Column(name="orderer_id"))
)
private MemberId memberId;
@Column(name = "orderer_name")
private String name;
}@Embeddable
public class ShippingInfo {
@Embedded
@AttributeOverrids({
@AttributeOverride(name = "zipCode", column= @Column(name="shipping_zipcode")),
@AttributeOverride(name = "address1", column= @Column(name="shipping_addr1")),
@AttributeOverride(name = "address2", column= @Column(name="shipping_addr2"))
})
private Address address;
@Column(name = "shipping_message")
private String message;
@Embedded
private Receiver receiver;
}- @Embedded를 이용해서 밸류 타입 프로퍼티를 설정
- 매핑 설정과 다른 컬럼 이름을 사용하기 위해 @AttributeOverride 애너테이션을 사용
기본 생성자
@Embeddable
public class Receiver{
@Column(name = "receiver_name")
private String name;
@Column(name = "receiver_phone")
private String phone;
protected Receiver(){} //JPA를 적용하기 위해 기본 생성자 추가
public Receiver(String name, String phone){
this.name = name;
this.phone = phone;
}
..// get 메서드 생략
}기본 생성자를 다른 코드에서 사용하면 값이 없는 온전하지 못한 객체를 만들게 된다. 이런 이유로 다른 코드에서 기본 생성자를 사용하지 못하도록 protected로 선언한다.
필드 접근 방식 사용
@Entity
@Access(AccessType.PROPERTY)
public class Order {
@Column(name = "state")
@Enumerated(EnumType.STRING)
public OrderState getState() {
return state;
}
public void setState(OrderState state) {
this.state = state;
}
}밸류 타입을 불변으로 구현하려면 set 메서드 자체가 필요 없는데 JPA의 구현 방식 때문에 공개 set 메서드를 추가하는 것도 좋지 않다.
객체가 제공할 기능 중심으로 엔티티를 구현하게끔 유도하려면 JPA 매핑 처리를 프로퍼티 방식이 아닌 필드 방식으로 선택해서 불필요한 get/set 메서드를 구현하지 말아야 한다.
@Entity
@Access(AccessType.FIELD)
public class Order {
@EmbeddedId
private OrderNo number;
@Column(name = "state")
@Enumerated(EnumType.STRING)
private OrderState state;
... // cancel(), changeShippingInfo() 등 도메인 기능 구현
... // 필요한 get메서드 제공
}JPA 구현체인 하이버네이트는 @Access를 이용해서 명시적으로 접근 방식을 지정하지 않으면 @Id나 @EmbeddedId가 어디에 위치 했느냐에 따라 접근 방식을 결정한다.
AttributeConverter를 이용한 밸류 매핑 처리
package javax.persistence;
public interface AttributeConverter<X,Y> {
public Y convertToDatacaseColumn(X attribute);
public X convertToEntityAttribute(Y dbData);
}@Converter(autoApply = true)
public class MoneyConverter implements AttributeConverter<Money, Integer> {
@Override
public Integer convertToDatabaseColumn(Money money) {
if(money == null) return null;
else return money.getValue();
}
@Override
public Money convertToEntityAttribute(Integer value) {
if(value == null) return null;
else return new Money(value);
}
}@Converter(autoApply = true) false 일 시, 사용할 컨버터를 직접 지정해야 한다.
밸류 컬렉션: 별도 테이블 매핑
밸류 컬렉션을 별도 테이블로 매핑할 때는 @ElementCollection과 @CollectionTable을 함께 사용한다.

@Entity
@Table(name = "purchase_order")
public class Order {
...
@ElementCollection
@CollectionTable(name = "order_line",
joinColumns = @JoinColumn(name = "order_number"))
@orderColumn(name = "line_idx")
private list<OrderLine> orderLines;
}
@Embeddable
public class OrderLine {
@Embedded
private ProductId productId;
...
}밸류 컬렉션: 한 개 칼럼 매핑
도메인 모델에는 이메일 주소 목록은 Set으로 보관하고 DB에는 한 개 칼럼에 콤마로 구분해서 저장해야 할 때가 있다. 이때 AttributeConverter를 사용하면 밸류 컬렉션을 한 개 칼럼에 쉽게 매핑할 수 있다. 단 AttributeConverter를 사용하려면 밸류 컬렉션을 표현하는 새로운 밸류 타입을 추가해야 한다.
public class EmailSet {
private Set<Email> emails = new HashSet<>();
private EmailSet() {}
private EmailSet(Set<Email> emails) {
this.emails.addAll(emails);
}
public Set<Email> getEmails() {
return Collections.unmodifiableSet(emails);
}
}
@Converter
public class EmailSetConveter implements AttributeConveter<EmailSet, String> {
@Override
public String convertToDatabaseColumn(EmailSet attribute) {
if(attribute == null) return null;
return attribute.getEmails().stream()
.map(Email::toString)
.collect(Collectors.joining(","));
}
@Override
public EmailSet convertToEntityAttribute(String dbData) {
if(dbData == null) return null;
String[] emails = dbData.split(",");
Set<Email> emailSet = Arrays.stream(emails)
.map(value -> new Email(value))
.collect(toSet());
return new EmailSet(emailSet);
}
}@Column(name = "emails")
@Convert(converter = EmailSetConverter.class)
private EmailSet emailSet;
밸류를 이용한 ID 매핑
JPA에서 식별자 타입은 Serializable 타입이어야 하므로 식별자로 사용할 밸류 타입은 Serializable 인터페이스를 상속받아야 한다. 밸류 타입으로 식별자를 구현할 때 얻을 수 있는 장점은 식별자에 기능을 추가할 수 있다는 점이다.
@Embeddable
public class OrderNo implements Serializable {
@Column(name = "order_number")
private String number;
public boolean is2ndGeneration() {
return number.startsWith("N");
}
...
}
별도 테이블에 저장하는 밸류 매핑
루트 엔티티 외에 또 다른 엔티티가 있다면 진짜 엔티티인지 의심해 봐야 한다. 단지 별도 테이블에 데이터를 저장한다고 해서 엔티티인 것은 아니다. 주문 애그리거트도 OrderLine을 별도 테이블에 저장하지만 OrderLine 자체는 엔티티가 아니라 밸류다.
밸류가 아니라 엔티티가 확실하다면 해당 엔티티가 다른 애그리거트는 아닌지 확인해야 한다.
ex) 상품 상세 화면을 보면 상품 정보와 고객 리뷰 둘 다 다른 애그리거트에 속한 엔티티이다.
애그리거트에 속한 객체가 밸류인지 엔티티인지 구분하는 방법은 고유 식별자를 갖는지를 확인하는 것이다.

@SecondaryTable을 이용하면 아래 코드를 실행할 때 두 테이블을 조인해서 데이터를 조회한다.
@Entity
@Table(name = "article")
@SecondaryTable(
name = "article_content",
pkJoinColumns = @PrimaryKeyJoinColumn(name = "id")
)
public class Article {
@Id
private Long id;
...
@AttributeOverrides({
@AttributeOverride(name = "content",
column = @Column(table = "article_content")),
@AttributeOverride(name = "contentType",
column = @Column(table = "artible_content"))
})
private ArticleContent content;
...
}밸류 컬렉션을 @Entity로 매핑하기
개념적으로 밸류인데 구현 기술의 한계나 팀 표준 때문에 @Entity를 사용해야 할 때도 있다.
JPA는 @Embeddable 타입의 클래스 상속 매핑을 지원하지 않는다. 대신 @Entity를 이용한 상속 매핑으로 처리해야 한다. 엔티티로 관리되므로 식별자 필드가 필요하고 타입 식별 칼럼을 추가해야 한다.
Image가 @Entity이므로 목록을 담고 있는 Product는 아래과 같이 @OneToMany를 이용해서 매핑을 처리한다.
@Entity
@Table(name = "product")
public class Product{
@EmbeddedId
private ProductId id;
private String name;
@Convert(converter = MoneyConverter.class)
private Money price;
private String detail;
@OneToMany(cascade = {CascadeType.PERSIST, CascadeType.REMOVE},
orphanRemoval = true)
@JoinColumn(name = "product_id")
@OrderColumn(name = "list_idx")
private List<Image> images = new ArrayList<>();
...
public void changeImages(List<Image> newImages){
images.clear();
images.addAll(newImages);
}
}하이버네이트는 @Embeddable 타입에 대한 컬렉션의 clear() 메서드를 호출하면 컬렉션에 속한 객체를 로딩하지 않고 한 번의 delete 쿼리로 삭제 처리를 수행한다. 따라서 애그리거트의 특성을 유지하면서 이 문제를 해소하려면 결국 상속을 포기하고 @Embeddable로 매핑된 단일 클래스로 구현해야 한다. 타입에 따라 다른 기능을 구현하려면 다음과 같이 if-else를 써야 한다.
@Embeddable
public class Image{
@Column(name = "image_type")
private String imageType;
@Column(name = "image_path")
private String path;
@Temporal(TemporalType.TIMESTAMP)
@Column(name = "upload_time")
private Date uploadTime;
...
public boolean hasThumbnail(){
//성능을 위해 다형을 포기하고 if-else로 구현
if(imageType.equals("II"){
return true;
}else {
return false;
}
}
}코드 유지 보수와 성능의 두 가지 측면을 고려해서 구현 방식을 선택해야 한다.
ID 참조와 조인 테이블을 이용한 단방향 M:N 매핑
@Entity
@Table(name = "product")
public class Product {
@EmbeddedId
private ProductId id;
@ElementCollection
@CollectionTable(name ="product_category",
joinColumns = @JoinColumn(name = "product_id"))
private Set<CategoryId> categoryIds;
...
}애그리거트를 직접 참조하는 방식을 사용했다면 영속성 전파나 로딩 전략을 고민해야 하는데 ID 참조 방식을 사용함으로써 이런 고민을 없앨 수 있다.
애그리거트 로딩 전략
JPA 매핑을 설정할 때 항상 기억해야 할 점은 애그리거트에 속한 객체가 모두 모여야 완전한 하나가 된다는 것이다.
//product는 완전한 하나여야 한다.
Product product = productRepository.findById(id);보통 조회 성능 문제 때문에 즉시 로딩 방식을 사용하지만 이렇게 조회되는 데이터 개수가 많아지면 즉시 로딩 방식을 사용할 때 성능(실행 빈도, 트래픽, 지연 로딩 시 실행 속도 등)을 검토해 봐야 한다.
애그리거트가 완전해야 하는 이유 두가지
1. 상태를 변경하는 기능을 실행할 때 애그리거트 상태가 완전해야 한다
2. 표현 영역에서 애그리거트의 상태 정보를 보여줄 때 필요하다
JPA는 트랜잭션 범위 내에서 지연 로딩을 허용하기 때문에 다음 코드처럼 실제로 상태를 변경하는 시점에 필요한 구성요소만 로딩해도 문제가 되지 않는다.
@Transactional
public void revmoeoptions(ProductId id, int optIdxToBeDeleted) {
//Product를 로딩/ 컬렉션은 지연 로딩으로 설정했다면 Option은 로딩되지 않음
Product product = productRepository.findByid(id);
// 트랜잭션 범위이므로 지연 로딩으로 설정한 연관 로딩 가능
product.removeOption(optIdxToBeDeleted);
}
@Entity
public class Product {
@ElementCollection(fetch = FetchType.LAZY)
@CollectionTable(name = "product_option",
joinColumns = @JoinColumn(name = "product_id"))
@OrderColumn(name = "list_idx")
private List<Option> options = new ArrayList<>();
public void removeOption(int optIdx) {
//실제 컬렉션에 접근할 때 로딩
this.options.remove(optIdx);
}
}일반적으로 상태를 변경하기 보다는 조회하는 빈도 수가 높다. 이런 이유로 애그리거트 내의 모든 연관을 즉시 로딩으로 설정할 필요는 없다. 물론, 지연 로딩은 즉시 로딩보다 쿼리 실행 횟수가 많아질 가능성이 더 높다. 따라서, 무조건 즉시 로딩이나 지연 로딩으로만 설정하기보다는 애그리거트에 맞게 즉시 로딩과 지연 로딩을 선택해야 한다.
애그리거트의 영속성 전파
- 저장 메서드는 애그리거트 루트만 저장하면 안 되고 애그리거트에 속한 모든 객체를 저장해야 한다
- 삭제 메서드는 애그리거트 루트뿐만 아니라 애그리거트에 속한 모든 객체를 삭제 해야 한다.
@OneToOne, @OneToMany는 cascade 속성의 기본값이 없으므로 cascade 속성값으로 CascadeType.PERSIST, CascadeType.REMOVE를 설정한다.
식별자 생성 기능
식별자는 크게 세 가지 방식 중 하나로 생성한다.
- 사용자가 직접 생성
- 도메인 로직으로 생성
- DB를 이용한 일련번호 사용
'IT서적 > 도메인 주도 개발 시작하기' 카테고리의 다른 글
| [도메인 주도 개발 시작하기] 6. 응용 서비스와 표현 영역 (0) | 2023.07.29 |
|---|---|
| [도메인 주도 개발 시작하기] 5. 스프링 데이터 JPA를 이용한 조회 기능 (0) | 2023.07.28 |
| [도메인 주도 개발 시작하기]3. 애그리거트 (0) | 2023.07.26 |
| [도메인 주도 개발 시작하기] 2. 아키텍처 개요 (0) | 2023.07.25 |
| [도메인 주도 개발 시작하기] 1.6 엔티티와 밸류 (0) | 2023.07.20 |


