
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- DDD
- react
- vue.js
- 알고리즘분석
- aop
- 이팩티브 자바
- 자료구조
- AWS RDS
- 자바
- 자바스터디
- 자바예외
- 혼공SQL
- SQL쿡북
- 스프링부트와AWS로혼자구현하는웹서비스
- java
- mysql
- 도메인 주도 개발 시작하기
- 기술면접
- MariaDB
- 알고리즘
- jpa
- 이펙티브자바
- 이펙티브 자바
- 클린코드
- CleanCode
- 인덱스
- 인프런백기선
- AWS
- 인프런김영한
- 네트워크
- Today
- Total
기록이 힘이다.
[SQL 쿡북] 10. 범위 관련 작업하기 본문
10.1 연속 값의 범위 찾기
select *
from V
--------------------------------------------------------------------
select proj_id, proj_start, proj_end
from (
select proj_id, proj_start, proj_end,
lead(proj_start)over(order by proj_id) next_proj_start
from V
) alias
where next_proj_start = proj_end
--------------------------------------------------------------------
<DB2, MySQL, PostgreSQL, SQL Server, Oracle>
select *
from (
select proj_id, proj_start, proj_end,
lead(proj_start)over(order by proj_id) next_proj_start
from v
)
where proj_id in ( 1, 4 )
--------------------------------------------------------------------
select *
from V
where proj_id <= 5
--------------------------------------------------------------------
select proj_id, proj_start, proj_end
from (
select proj_id, proj_start, proj_end,
lead(proj_start)over(order by proj_id) next_start
from V
where proj_id <= 5
)
where proj_end = next_start
--------------------------------------------------------------------
select proj_id, proj_start, proj_end
from (
select proj_id, proj_start, proj_end,
lead(proj_start)over(order by proj_id) next_start,
lag(proj_end)over(order by proj_id) last_end
from V
where proj_id <= 5
)
where proj_end = next_start
or proj_start = last_end
10.2 같은 그룹 또는 파티션의 행 간 차이 찾기
같은 부서의 사원 간 SAL 차이와 함께, 각 사원의 DEPTNO, ENAME 및 SAL을 반환하려고 합니다.(즉, 같은 DEPTNO 값을 가집니다.)
with next_sal_tab (deptno,ename,sal,hiredate,next_sal)
as
(select deptno, ename, sal, hiredate,
lead(sal)over(partition by deptno
order by hiredate) as next_sal
from emp )
select deptno, ename, sal, hiredate
, coalesce(cast(sal-next_sal as char), 'N/A') as diff
from next_sal_tab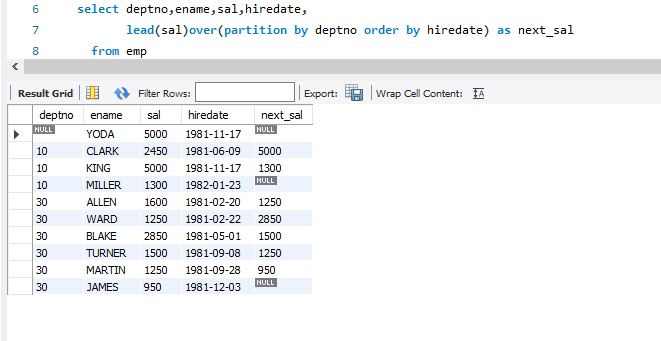
1. LEAD OVER 함수를 사용하여 부서 내 각 사원의 '다음' 급여를 찾는 것입니다. 각 부서에서 마지막으로 고용된 사원은 NEXT_SAL에 대해 NULL 값을 갖습니다.

2. 각 사원의 급여와, 같은 부서에서 바로 다음에 고용된 사원의 급여의 차이를 가져오는 것입니다.
<ORACLE>
select deptno,ename,sal,hiredate,
nvl(to_char(sal-next_sal),'N/A') diff
from (
select deptno,ename,sal,hiredate,
lead(sal)over(partition by deptno order by hiredate) next_sal
from emp
) X
--------------------------------------------------------------------
select deptno,ename,sal,hiredate,
lpad(nvl(to_char(sal-next_sal),'N/A'),10) diff
from (
select deptno,ename,sal,hiredate,
lead(sal)over(partition by deptno
order by hiredate) next_sal
from emp
where deptno=10 and empno > 10
)LEAD OVER 함수를 사용할 때 중복되는 시나리오를 논의해야 합니다.
insert into emp (empno,ename,deptno,sal,hiredate)
values (1,'ant',10,1000,to_date('17-NOV-2006'))
insert into emp (empno,ename,deptno,sal,hiredate)
values (2,'joe',10,1500,to_date('17-NOV-2006'))
insert into emp (empno,ename,deptno,sal,hiredate)
values (3,'jim',10,1600,to_date('17-NOV-2006'))
insert into emp (empno,ename,deptno,sal,hiredate)
values (4,'jon',10,1700,to_date('17-NOV-2006'))
select deptno,ename,sal,hiredate,
lpad(nvl(to_char(sal-next_sal),'N/A'),10) diff
from (
select deptno,ename,sal,hiredate,
lead(sal)over(partition by deptno
order by hiredate) next_sal
from emp
where deptno=10
)같은 날 고용된 사원 4명을 더 보여주는 상황, LEAD OVER 함수는 기본적으로 한 행 앞만 보기 때문에 중복 항목을 건너뛰지 않았다. 해법은 단순히 계산문제!

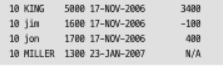
select deptno,ename,sal,hiredate,
lpad(nvl(to_char(sal-next_sal),'N/A'),10) diff
from (
select deptno,ename,sal,hiredate,
lead(sal,cnt-rn+1)over(partition by deptno
order by hiredate) next_sal
from (
select deptno,ename,sal,hiredate,
count(*)over(partition by deptno,hiredate) cnt,
row_number()over(partition by deptno,hiredate order by sal) rn
from emp
where deptno=10
)
)
LEAD OVER에 추가 매개변수를 전달하여 얼마나 앞서야할지 알 수 있다. CNT - RN +1은 11월 17일에 고용된 각 사원에서 밀러까지의 차이
select deptno,ename,sal,hiredate,
count(*)over(partition by deptno,hiredate) cnt,
row_number()over(partition by deptno,hiredate order by sal) rn
from emp
where deptno=10
--------------------------------------------------------------------
select deptno,ename,sal,hiredate,
lead(sal)over(partition by deptno
order by hiredate) incorrect,
cnt-rn+1 distance,
lead(sal,cnt-rn+1)over(partition by deptno
order by hiredate) correct
from (
select deptno,ename,sal,hiredate,
count(*)over(partition by deptno,hiredate) cnt,
row_number()over(partition by deptno,hiredate
order by sal) rn
from emp
where deptno=10
)첫 번째 쿼리를 살펴보면 CNT 값은 HIREDATE가 중복된 각 사원에 대해 HIREDATE에 대한 총 중복 수를 나타냅니다. RN 값은 DEPTNO 10의 사원에 대한 순위를 나타냅니다. 순위는 DEPTNO 및 HIREDATE로 분할되므로, 다른 사원의 HREDATE와 중복된 사원만 1보다 큰 값을 갖습니다. 순위는 SAL별로 정렬됩니다(임의로 SAL을 선택하였으며 EMPNO도 선택할 수 있습니다.)
이 쿼리를 적용하여 계산하면 LEAD OVER까지 정확한 차이를 계산했을 때의 효과를 명확하게 확인할 수 있습니다.

10.3 연속 값 범위의 시작과 끝 찾기
<ORACLE>

가장 간단한 접근 방식은 LAG OVER 윈도우 함수를 사용하는 것입니다. LAG OVER를 사용하여 각 이전 행의 PROJ_END가 현재 행의 PROJ_START와 같은지를 확인하면 행을 그룹으로 배치하는 데 도움이 됩니다. 그룹화되면 집계 함수 MIN 및 MAX를 사용하여 시작점과 끝점을 찾습니다.
select proj_grp, min(proj_start), max(proj_end)
from (
select proj_id,proj_start,proj_end,
sum(flag)over(order by proj_id) proj_grp
from (
select proj_id,proj_start,proj_end,
case when
lag(proj_end)over(order by proj_id) = proj_start
then 0 else 1
end flag
from V
) alias1
) alias2
group by proj_grp
select proj_id,proj_start,proj_end,
lag(proj_end)over(order by proj_id) prior_proj_end
from V
--------------------------------------------------------------------
select proj_id,proj_start,proj_end,
sum(flag)over(order by proj_id) proj_grp
from (
select proj_id,proj_start,proj_end,
case when
lag(proj_end)over(order by proj_id) = proj_start
then 0 else 1
end flag
from V
)10.4 값 범위에서 누락된 값 채우기
2005년 이후 10년 동안 매년 고용된 사원 수를 반환하려고 하지만, 사원이 고용되지 않은 연도도 있습니다.
지정된 연도에 사원이 고용되지 않은 경우, 해당 연도의 행은 EMP 테이블에 존재하지 않습니다. 테이블에 연도가 없으면 어떻게 어떤 수, 심지어 0을 반환할 수 있을까요? 해법은 외부 조인이 필요하다. 원하는 모든 연도를 반환하는 결과셋을 제공한 다음, EMP 테이블에 대해 카운트를 수행하여 각 연도에 고용된 사원이 있는지 확인해야 합니다.
<Oracle>
select x.yr, coalesce(cnt,0) cnt
from (
select extract(year from min(hiredate)over()) -
mod(extract(year from min(hiredate)over()),10) +
rownum-1 yr
from emp
where rownum <= 10
) x
left join
(
select to_number(to_char(hiredate,'YYYY')) yr, count(*) cnt
from emp
group by to_number(to_char(hiredate,'YYYY'))
) y
on ( x.yr = y.yr )
<PostgreSQL과 MySQL>
select y.yr, coalesce(x.cnt,0) as cnt
from (
select min_year-mod(cast(min_year as int),10)+rn as yr
from (
select (select min(extract(year from hiredate))
from emp) as min_year,
id-1 as rn
from t10
) a
) x
left join
(
select extract(year from hiredate) as yr, count(*) as cnt
from emp
group by extract(year from hiredate)
) y
on ( y.yr = x.yr )구문 차이가 있긴 하지만 접근 방식은 모든 해법에서 같습니다. 인라인 뷰 X는 먼저 가장 빠른 HIREDATE의 연도인 80년대 초창기 채용 연도를 찾고 매년을 반환합니다. 다음 단계는 가장 이른 연도와 가장 이른 연도의 계수 10의 차이에 RN -1을 추가하는 것입니다.
인라인 뷰 Y는 각 HIREDATE의 연도 및 해당 연도 동안 고용된 사원 수를 반환합니다.
마지막으로 인라인 뷰 Y를 인라인 뷰 X에 외부 조인하여 고용된 사원이 없는 경우에도 매년 반환하도록 합니다.
10.5 연속된 숫자값 생성하기
<DB2와 SQL Server>
with x (id)
as (
select 1
union all
select id+1
from x
where id+1 <= 10
)
select * from x
<Oracle>
select array id
from dual
model
dimension by (0 idx)
measures(1 array)
rules iterate (10) (
array[iteration_number] = iteration_number+1
)
<PostgreSQL>
select id
from generate_series (1, 10) x(id)
'SQL' 카테고리의 다른 글
| [SQL 쿡북] 12 보고서 작성과 재구성하기 (0) | 2023.04.27 |
|---|---|
| [SQL 쿡북] 11. 고급 검색 (0) | 2023.04.12 |
| [SQL 쿡북] 9.날짜 조작 기법 (0) | 2023.04.04 |
| [SQL 쿡북] 8. 날짜 산술 (0) | 2023.03.22 |
| [SQL 쿡북] 7. 숫자작업(18) (0) | 2023.03.18 |



